LLM / VLM アプリをどう開発し、どう提供するか
LLM / VLM アプリをどう開発し、どう提供するか 現実的な4つの開発アプローチを比較する ここから議論の軸をさらに明確にしたい。 本ストーリーの主題は、単なるローカルAIの概念整理ではない。 LLM / VLMを使ったアプリを開発し、利用者に提供すること。 この実務上の目的から逆算して、現時点で現実的な開発アプ...
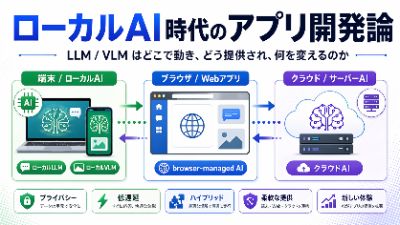
LLM / VLM アプリをどう開発し、どう提供するか 現実的な4つの開発アプローチを比較する ここから議論の軸をさらに明確にしたい。 本ストーリーの主題は、単なるローカルAIの概念整理ではない。 LLM / VLMを使ったアプリを開発し、利用者に提供すること。 この実務上の目的から逆算して、現時点で現実的な開発アプローチを整理すると、主要な選択肢は次の4つに分かれる。 クラウド / サーバー推論型 OS提供オンデバイスAI活用型 独自ローカルモデル組み込み / 連携型 ブラウザ管理AI活用型 クラウド / サーバー推論型 これは最も一般的な方式である。 アプリは利用者の入力をサーバーへ送り、サーバー側でLLM / VLMを実行し、結果を返す。 できること 高性能なモデルを利用しやすい 重いVLMや長文処理に強い モデル更新を一元管理できる 多数ユーザーへの安定提供がしやすい 弱いこと 推論時にネットワーク必須 入力データが端末外へ出る 推論コストとサーバー負荷が発生する オフライン利用が難しい 向いている用途 高精度重視の業務アプリ 文書理解や重い画像解析 企業向けSaaS 組織横断の一元管理が必要なサービス OS提供オンデバイスAI活用型 これは、OSやプラットフォームが提供するローカルAI機能をアプリから利用する方式である。 多くの場合、利用者に提供する形はネイティブアプリになる。 できること 低遅延なローカル推論 端末内完結 プライバシー配慮型の設計 軽量なテキスト処理や画像理解 弱いこと OSベンダーの提供範囲に縛られる 任意モデルを自由に選べない Apple / Google などで実装差が大きい クロスプラットフォーム共通化が難しい 向いている用途 スマホアプリ 端末内完結が求められる補助機能 軽量なローカルLLM / VLM活用 個人情報を外へ出したくない用途 独自ローカルモデル組み込み / 連携型 これは、開発者自身がローカルLLM / VLMを直接扱う方式である。 ネイティブアプリへモデルを組み込むか、ローカルランタイムと連携する。 できること モ...