ローカルLLMとサーバーLLMの位置関係
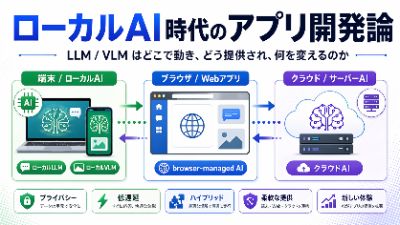
ローカルLLMとサーバーLLMの位置関係 端末・ブラウザ・クラウド・ネットワークをまず整理する 生成AIの議論は、すぐに「どのモデルが優れているか」に流れがちである。 しかし、実際にアプリを開発し、利用者へ提供する立場で最初に整理すべきなのは、そのAIがどこで動くのか である。 この前提を曖昧にしたまま話を進めると、...
ローカルLLMとサーバーLLMの位置関係 端末・ブラウザ・クラウド・ネットワークをまず整理する 生成AIの議論は、すぐに「どのモデルが優れているか」に流れがちである。 しかし、実際にアプリを開発し、利用者へ提供する立場で最初に整理すべきなのは、そのAIがどこで動くのか である。 この前提を曖昧にしたまま話を進めると、ローカルLLM、ブラウザLLM、サーバーLLM、オンデバイスAI、ネイティブAIといった言葉が混線し、設計の議論もぶれてしまう。 まず押さえるべき軸は、次の3つである。 推論はどこで実行されるのか 利用者の入力データはネットワークを通るのか モデルを誰が管理するのか ローカルLLMとは何か ローカルLLMとは、PCやスマートフォンなど、利用者の端末内で推論が完結するLLM のことである。 この場合、利用者が入力したテキストや画像は、推論のために外部サーバーへ送信されない。 少なくとも推論時のデータ経路は、端末内で閉じている。 ローカルLLMには、大きく2つの見方がある。 1つは、ネイティブアプリやローカルランタイムが直接使うローカルLLM である。 たとえば、PCアプリやスマホアプリがOSのAI機能や独自に組み込んだモデルを使うケースがこれにあたる。 もう1つは、ブラウザが管理するローカルAI である。 こちらも端末内で動くという意味ではローカルだが、モデル管理の主体はアプリではなくブラウザ側にある。 サーバーLLMとは何か これに対してサーバーLLMは、利用者の入力をネットワーク経由でサーバー側へ送り、サーバー上で推論し、その結果を返す方式 である。 これは現在のクラウドAIやAI SaaSの中心的な方式でもある。 この方式の特徴は、重いモデルや高性能なVLMを安定して使えることにある。 一方で、入力データは当然ネットワークを通過する。 ここで重要なのは「流出するかどうか」という単純な話ではなく、データが端末の外へ出る設計なのか、端末内で閉じる設計なのか という違いである。 なぜネットワーク経路が重要なのか この違いは、単なる技術方式の差ではない。 アプ...